Apply Neo4j Similarity Algorithm to analyse Chess “openings”
May 14: Chess, One Month Graph Challenge
Welcome word
In this series of small posts I do one simple graph daily. Domain model of graph somehow related to day’s history, some historical event, celebration or person. I do this challenge to learn Neo4j Data Modeling and Cypher. Every day. One month. Follow me. Maybe you will be inspired and next month would be yours One Month Graph Challenge. #OMGChallenge
Domain model
May 14 is a birthday of Austrian chess player, the first World Chess Chamion — Wilhelm Steinitz. Today I plan to build a small graph in chess domain model in honor of this great chess theorist.
I also want to add, that chess is close topic for me. I play at chess.com as amateur for a year maybe, and just a few days ago I reached 1000 games and keep ranking around 1200. So far, so good.
So, what I want to do? To build a small graph and analyse my year stats of chess data. I want to know how much similar games I won? How different my games in general?
Graph
Ok. I need my chess stats. chess.com have a public API ready for my needs.
UNWIND ["2018/09", "2018/10", "2018/11", "2018/12", "2019/01", "2019/02", "2019/03", "2019/04", "2019/05"] as ym
WITH ("https://api.chess.com/pub/player/vladbatushkov/games/" + ym) as url
CALL apoc.load.json(url) YIELD value
UNWIND value.games as game
WITH game.time_class as type, game.pgn as raw, game.white.result as whiteResult, game.white.username as whiteUser, game.black.result as blackResult, game.black.username as blackUser
WHERE type = "blitz"
WITH whiteUser, whiteResult, blackUser, blackResult, apoc.text.regexGroups(raw, "(openings\\S\\S\\d\\d-)(\\S+)(\")")[0][2] as opening
, apoc.text.replace(coalesce(apoc.text.regexGroups(raw, "(\\n\\n)(.+)( [01]-[01])")[0][2], ""), "(\\{.{1,17}\\})", "") as moves
WHERE moves <> ""
MERGE (g:Game { whiteUser: whiteUser, whiteResult: whiteResult, blackUser: blackUser, blackResult: blackResult, opening: opening, moves: moves })Isn’t it a miracle? Magic of regex mixed with APOC power and now I can analyse 9 months of my 979 blitz games.
I think, I should start with something simple. How much times I played white vs black:
MATCH (g1:Game)
WHERE g1.whiteUser = "vladbatushkov"
WITH count(g1.whiteUser) as white
MATCH (g2:Game)
WHERE g2.blackUser = "vladbatushkov"
RETURN white, count(g2.blackUser) as black
Nothing interesting. It should be equal, game engine must take care about user game balance. Now let’s see, how much I won with one or another well known opening. By the way, if you don’t know what is “opening”, in a two words it is a defined sequence of several moves. Idea behind repeating well known opening moves in most cases is to got advantage in position in early game stage.
MATCH (g:Game)
WHERE (g.whiteUser = "vladbatushkov" AND g.whiteResult = "win") OR (g.blackUser = "vladbatushkov" AND g.blackResult = "win")
RETURN coalesce(g.opening, "UNKNOWN") as opening, count(g.opening) as count
ORDER BY count DESC
LIMIT 10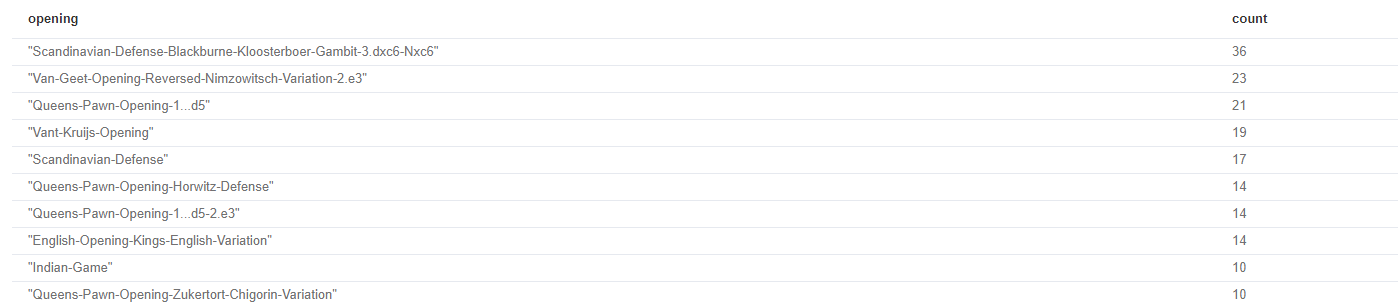
Yes, it is true, I love to play Scandinavian Defense in Blackburne-Kloosterboer Gambit variation. It gives me huge open space to attack white opponent. I gives for free 2 pawns and risk a lot, but it gives me some benefits in future as you can see.
Why I talking about opening? Opening is a key to build a similarity relationships between games. I can look into the similarity of sequence of first moves to determine similarity relationship between game nodes, and I guess I must got very same results. Let’s check this hypothesis.
Before similarity check I set a property movesAsColl with first 10 moves, this prop will be used for future comparison mechanism.
MATCH (g:Game)
UNWIND split(g.moves, " ") as move
WITH apoc.text.replace(move, "\\d\\.{1,3}", "") as move, g
WHERE move <> ""
WITH id(g) as id, collect(move) as moves, g
WITH id, moves, size(moves) as total, g
WHERE total >= 10
SET g.movesAsColl = moves[0..10]Similarity algorithm need a numeric collection, so now I need one more step to convert moves like “e4”, “Nf6” into numbers (id code of move).
MATCH (g:Game)
UNWIND g.movesAsColl as move
WITH collect(move) as moves
WITH apoc.coll.toSet(moves) as result
MATCH (g:Game)
UNWIND g.movesAsColl as move
WITH { code: apoc.coll.indexOf(result, move), move: move } as item, g
WITH collect(item.code) as codes, g
SET g.movesAsCodes = codesNow game nodes ready to be measured on similarity condition. I set WHERE condition to look at similarity between 0.5 and 1.
MATCH (g1:Game)
MATCH (g2:Game)
WHERE id(g1) <> id(g2)
WITH g1, g2, algo.similarity.jaccard(g1.movesAsCodes, g2.movesAsCodes) AS similarity
WHERE similarity > 0.5 AND similarity < 1 AND g1.opening <> g2.opening
RETURN g1.opening, g1.movesAsColl, g2.opening, g2.movesAsColl, similarity
ORDER BY similarity DESC
LIMIT 10
For this subgroup, you can see, that it gives me much more clarity, that the position on board is similar. Even when opening is different as it is not match the original moves sequence. Position is both games still very close to each other. This is really cool. Save similarity as relationship:
MATCH (g1:Game)
MATCH (g2:Game)
WHERE id(g1) <> id(g2)
WITH g1, g2, algo.similarity.jaccard(g1.movesAsCodes, g2.movesAsCodes) AS similarity
WHERE similarity > 0.5
MERGE (g1)-[:SIMILAR_TO { weight: similarity }]->(g2)Now, I can recalculate my win stats based on similarity, must be wider than matching by opening name. Results by matching of first 10 moves.
MATCH (g:Game)-[s:SIMILAR_TO]-()
WHERE s.weight > 0.5
AND (g.whiteUser = "vladbatushkov" AND g.whiteResult = "win") OR (g.blackUser = "vladbatushkov" AND g.blackResult = "win")
WITH id(g) as id, s.weight as weight, g.opening as opening
WITH { wins: collect(id), openings: collect(opening), weight: weight } as item
RETURN item.weight as similarity, size(apoc.coll.toSet(item.wins)) as totalWins, apoc.coll.toSet(item.openings) as includesOpenings
Resume
Chess analysis is interesting and hard. I spand whole evening on discovering similarity of “opening”. But I have more ideas now to discover. For example, would be awesome to wirte a query, that can predict how good my current position is. It also would be wonderful to ask for suggestion for the next move. Not a blunder one, for sure, but a good move.
So, I will continue investigate this topic and improve my current results in the nearest future. Look for Updates of this article or maybe a new article on this cool topic.
Similar topics
Neo4j graph Data Modeling of Star Wars Universe with APOC load json
Simple example of N-ary relationship to understand basics of Neo4j Graph Data Modeling
Initial Neo4j Graph Data Modeling of Train Ticket Booking System
Unusual use of Neo4j Common Neighbors Algorithm on people community graph
Neo4j Shortest Path and Dijkstra Algorithms
Build a Neo4j Graph of Moscow Metro Map with Spatial Values and Shortest Path Algorithm